Sensitive information such as personal data presents data analysts with legal and technical challenges. Preparing data in compliance with data protection regulations – from anonymisation to test data management – is becoming a key skill. This article highlights proven strategies, tools and technologies for preparing sensitive data for use in AI projects whilst ensuring compliance with the GDPR.
Introduction
Good data quality forms the foundation of every successful AI application. Poor-quality data inevitably leads to flawed models and unreliable results. Experience shows that experts still spend around 80% of their time on data preparation and only 20% on analysis and decision-making. The data pre-processing process can be extensive and complex, consisting of several steps.
By using AI-supported tools, this effort can be drastically reduced, leaving more time for important analysis tasks. Modern AI pipelines typically go through the following steps: data collection, profiling, cleansing, harmonisation and transformation. Typical tasks include collecting raw data, identifying and removing duplicates or erroneous entries, and standardising formats. Each of these sub-processes increases the reliability of the data for machine learning models. If these steps are implemented consistently, the company lays the foundation for predictive analytics and AI-supported automation.
Challenges in processing sensitive data: Focus on data protection and data quality
When processing sensitive data, companies face several challenges relating to data protection and data quality. Firstly, personal data (e.g. name, address, national insurance number) carries legal risks. Under the GDPR, this data must be either anonymised or at least pseudonymised in order to be processed further.
Anonymisation vs. pseudonymisation
These are two distinct methods for reducing personal identifiers in datasets, each with different legal and technical implications:
- Anonymisation means that personal data is altered in such a way that identification of the data subject is permanently ruled out – neither directly nor indirectly (e.g. through combination with other data). Under the GDPR, anonymised data is no longer considered personal data and is therefore no longer subject to data protection law. It is not possible to trace the data back to the original dataset.
- Pseudonymisation, on the other hand, replaces identifying characteristics (e.g. name, customer number) with codes or placeholders, whilst the link to the original data remains possible via a secret key (e.g. a mapping table). Pseudonymised data therefore continues to be regarded as personal data and is subject to the GDPR – it merely offers additional protection during processing. Only anonymised data is completely exempt from data protection.
Furthermore, a large proportion of the data collected remains unused within the organisation (dark data). Gartner estimates that information which is routinely generated but not used (e.g. old log files or emails) accounts for more than half of data holdings.
Furthermore, poor data quality undermines AI results. Common issues include missing values, typos or format inconsistencies.
Ensuring consistent, complete datasets is therefore essential. When dealing with sensitive data, data engineers must also ensure that subsequent merges do not lead to re-identification. Overall, handling sensitive data requires particular care: in addition to the significant effort involved in data cleansing, data protection entails technical and organisational hurdles.
Strategies for data anonymisation and masking
A wide variety of anonymisation methods are used when handling sensitive data. Important methods include, for example:
- Pseudonymisation: This involves replacing direct personal identifiers with pseudonyms and storing a mapping table separately. The original dataset thus remains reproducible. Disadvantage: Under the GDPR, pseudonymised data is still considered personal data and can be traced back with additional effort.
- Data masking: Masked datasets retain the structure and format of the original data but contain falsified values. Real data is replaced by random characters to safeguard confidentiality. In practice, however, the statistical significance is often reduced.
- Generalisation/Aggregation: Values are generalised into less precise categories (e.g. age data grouped into five-year intervals). This reduces the identifiability of individual data records – however, if applied too broadly, it can degrade data quality to such an extent that data usability suffers.
- Perturbation (noise): Original values are slightly altered by random noise (e.g. rounding or adding small random components). This method subtly distorts individual data points, whilst the overall data patterns remain largely intact. However, insufficient noise addition may allow conclusions to be drawn.
- Tokenisation: Specific sensitive fields (e.g. credit card numbers) are replaced by non-reversible tokens. This preserves the structural properties (format, length) whilst making re-identification more difficult.
- Synthetic data generation: Modern AI tools can generate entirely new datasets whose structure and statistical distribution resemble the original data. This synthetic data completely replaces personal data with fictitious values, thereby ensuring compliance with data protection laws.
- Homomorphic encryption (advanced): This involves converting data into encrypted formats that still allow calculations to be performed. Calculations on this ‘encrypted’ data ultimately yield the correct result without the actual plaintext data ever being disclosed. However, this method requires specialist knowledge and is computationally intensive.
Modern anonymisation tools often combine these techniques to optimise data protection and data quality. It is always important to strike an appropriate balance: the data must be anonymised sufficiently so that individuals cannot be traced back, yet remain meaningful for AI analyses.
Test data management and data masking with IRI Voracity
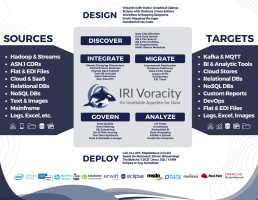
For test data management and data masking, it is best to use specialised tools. These offer dedicated functions designed for the task and thus speed up the work. One such tool is, for example, IRI Voracity (JetSoftware). It is an integrated data management platform that offers specific functions for test data management (TDM) and data protection. It combines data discovery (profiling, classification), data integration, data migration, data cleansing, data governance and analytics within an Eclipse-based development environment (Fig. 1).
Voracity covers all key methods of test data management, i.e. from pure data synthesis through to subsetting and data virtualisation. Within the platform, developers can create intelligently distributed test data sets without having to access original data. The following use cases and methods are supported:
- Synthetic test data generation: With IRI RowGen, completely new datasets can be generated that meet the structural and relational constraints (DDL constraints) of the target databases. RowGen supports over 100 data types and common file formats (e.g. CSV, XML, JSON, HL7, Excel, BLOBs). This allows test data tables or files to be populated with realistic field values according to specified patterns and distributions.
- Database subsetting: Voracity can reduce database tables to representative subsets. References and foreign keys are preserved in the process. This also applies when subsets are formed across different tables. The use of subsetting saves storage space and enables testing with smaller, yet database-consistent data sets.
- Masking of existing data: Production or test data can be anonymised using FieldShield (for relational tables and structured files), CellShield (for Excel) or DarkShield (for semi-structured/unstructured data such as text, images, BLOBs). In this process, sensitive values (e.g. names, addresses, IDs) are rendered unrecognisable in accordance with data protection regulations through encryption, pseudonymisation or replacement with random or consistent values, whilst the underlying structure remains intact (Table 1).
These methods allow test databases to be populated securely and realistically for functional tests, stress tests or continuous integration processes. The data can originate from a wide variety of sources, ranging from mainframe systems and relational database systems (Oracle, SQL Server, DB2, PostgreSQL) to modern big data formats (Kafka, NoSQL). Users employ the visual IRI Workbench (Eclipse) to design jobs, which are then executed without programming via the engines running in the background.
| Tool | Task |
| IRI Field | Shield for structured data (databases, CSV/fixed-file tables), offers profiling, detection and a variety of masking algorithms (e.g. format-preserving encryption, pseudonymisation, permutation, randomisation) |
| IRI DarkShield | for semi-structured and unstructured data sources (text, documents, JSON, BLOBs, images), identifies personal data (e.g. names, account numbers) in files and media, and removes or anonymises it. |
| IRI CellShield | for Excel tables masks or encrypts personal data columns and generates audit trails of changes |
Table 1: Data masking tools in Voracity.
The tools operate using metadata and rules. Fields can be automatically located through scanning and classification. Suitable transformations can then be selected for each field type (e.g. hashing, replacement with fictitious data, obfuscation). The result is anonymous datasets that are statistically and structurally similar to the original data but no longer contain any sensitive information. In practice, this means: production data is mirrored, for example, for a development copy, whereby all personal data fields are replaced according to defined masking strategies. The anonymised copy can then be securely shared or tested. A key feature is the preservation of referential integrity during masking.
Referential integrity and data masking
In a database context, referential integrity refers to the consistency of relationships between tables – typically via foreign keys. If, for example, a customer number in an order table refers to an entry in the customer table, this relationship must not become invalid as a result of data changes. In the context of data masking, this means: When sensitive data (such as customer numbers, ID card numbers or National Insurance numbers) is replaced, encrypted or pseudonymised, these transformations must be applied consistently across all affected tables. Otherwise, foreign key relationships would ‘break’ – for example, an order table might refer to a customer entry that no longer exists or has been masked differently. An example:
- Table A (Customers) contains: Customer No. `123` → Name `Müller`
- Table B (Orders): Customer No. `123` → Order `#A9`
- If `123` is now masked, the same replacement value must be generated in both tables, e.g. `KX54PZ`.
Referential integrity in masking means that the relational logic of the original data is preserved even after anonymisation – a crucial aspect for test data, migrations or data analysis.
In this way, customer or social security numbers, for example, can be pseudonymised consistently without ‘breaking’ databases. Further key features of data masking in Voracity include auditing and compliance support. The applications log which masking rules have been applied to demonstrate compliance with audit requirements.
Data masking in practice: tasks, methods and implementation
In this section, we provide an insight into the tasks and typical approach to data masking. The tool used here is IRI FieldShield, typically via the IRI Workbench (an Eclipse-based development environment). The graphical user interface enables users to visually identify sensitive fields in structured data sources and transform them in a targeted manner. Using wizards and context menus, masking rules such as encryption, hashing, tokenisation or pseudonymisation can be configured on a field-by-field basis – without the need for in-depth programming knowledge. Particularly convenient is the automatic detection of personal data fields (e.g. names, addresses, account numbers), which are identified and marked by rule-based classifiers. Typical masking functions include, for example:
- Format-preserving encryption: encryption whilst retaining the original format, for example: DE8937040044... → FE3729044423…
- Tokenisation: replaces values with unique, non-reversible tokens, for example: 123456 → KX9FZP
- Pseudonymisation: replacing personal data with realistic alternatives, for example: John Smith → Luke Becker
- Masking (substring): partial redaction of sensitive data, for example: Sample Street 8 → ***** Street 8
- Hashing (SHA-256 etc.): irreversible conversion of values, for example: 123456 → 2c1743a...
- Random value replacement: filling with fictitious, non-real but format-compatible values, for example: Anna → Claudia or 02/03/1990 → 19/08/1979
- Consistency preservation: the same input values result in identical outputs across all tables, for example: 123456 → always XK23M9
The masking jobs created are saved as reusable scripts and can be executed directly from the Workbench or integrated into automated workflows (Fig. 3).
In addition, FieldShield offers a Java and .NET SDK, which can be used to integrate masking functions into custom applications, microservices or middleware. This allows data masking to be implemented both manually via the GUI and fully automatically as part of ETL processes (ETL = Extract, Transform, Load) or CI/CD pipelines. An example of data masking could be illustrated as shown in Table 2 & 3.
| Data source: customers.csv | ||
| Column overview: | ||
| Customer number | => | Tokenisation |
| Name | => | Pseudonymisation |
| Address | => | Masking (partial string) |
| IBAN | => | AES-256 encryption |
| Customer status | => | No masking |
Preview
| Customer number | Name | Address | IBAN |
| KX34Z | Peter M. | ***** Street 10 | ************78 |
| MF22Q | Julia R. | ***** Avenue 55 | ************56 |
Tables 2 & 3: Example of data masking for customer data.
The graphical user interface allows for the targeted selection and transformation of columns. In the preview, the user can immediately see what the masked data looks like.
Legal requirements for AI projects under the GDPR: data protection, consent and anonymisation
In the EU, the GDPR regulates the handling of personal data very strictly. For AI projects, this means: Privacy by Design and Privacy by Default. It must be ensured right from the design stage that as little personal information as possible is processed. Pseudonymised data is still considered personal data – only true anonymisation removes the data protection obligations. The Federal Data Protection Act and the GDPR require an explicit legal basis (e.g. consent or contract) for every use of data during the development process.
Particularly in software development and testing, the Federal Commissioner for Data Protection and Freedom of Information (BfDI)[4] emphasises that no special rules apply here: under Article 25 of the GDPR, processing must be designed in such a way “that, as a rule, no personal data or less personal data is processed than during processing in production”. In other words: DevOps teams should, as a rule, only use anonymised or depersonalised data. All data protection principles (purpose limitation, data minimisation, storage limitation, etc.) remain fully applicable. Therefore, best practice involves: always identifying whether data can be anonymised; maintaining audit logs of data origins; storing test data in encrypted form; and restricting access to the data. Only in this way can AI projects comply not only with technical but also with legal requirements. Data protection authorities emphasise that, when it comes to test data, the most data-protection-friendly option must always be chosen. According to the BfDI, the following sequence of checks applies: First, it should be checked whether tests can be carried out using anonymous data (completely devoid of any personal reference). If this is not possible, pseudonymised data should be used. Only if neither anonymised nor pseudonymised data is feasible may unaltered personal data be used in exceptional cases. In practice, this means that synthetic or depersonalised test data should always be used wherever possible.
A test data catalogue is also recommended as best practice: teams define once and for all the fields that need to be obfuscated in the test and specify which data exchange formats (CSV, JSON, etc.) are to be used. Automated pipelines generate test sets according to the same scheme as required. Such standardised test data processes enable the iterative development of CI/CD pipelines in which automated testing is also possible in compliance with data protection regulations. Careful administration of the test data (versioning, encryption of the test database) rounds off the management process.
Sources of error and best practices in data preparation
Incomplete or inconsistent data sets cause incorrect AI results (“garbage in, garbage out”). Thus, inadequate cleaning inevitably leads to faulty models and decisions. Even seemingly harmless changes can be critical: crude anonymisation methods that remove essential data points severely limit the usefulness of the data. Sources of error can arise from typos, missing attributes, delayed updates or unnoticed format changes. Outdated metadata (dark data) often conceals information that is missing from analyses. Furthermore, manual steps or unnoticed transformations carry the risk that data will no longer be reproducible.
To avoid these errors, a number of best practices have been established: Firstly, a clear plan and defined objectives for data maintenance are required. Regular reviews and continuous data maintenance (monitoring) prevent inconsistent data from entering the system. Automated cleansing tools detect typical problems such as duplicates or invalid values and resolve them routinely. Maintaining data profiles is helpful in this regard: analysis tools such as the profiling functions in Voracity capture statistical metrics (min/max, proportion of zeroes, etc.) and flag outliers.
It is also important to maintain referential integrity during transformation (see above). This prevents violations of relationships in data schemas. Finally, comprehensive documentation and transparency are essential; that is, all data quality rules, anonymisation procedures and data flows should be documented and versioned. Organisations benefit from implementing data governance standards – ensuring that all stakeholders (developers, data scientists, data protection officers) are aware of and can control the state of the data.
Conclusion
Data that is both ‘clean’ and anonymised is the decisive factor for the success of AI projects. Only those who place a high value on data quality can fully exploit its potential. The use of AI in data preparation makes it possible to automate time-consuming routine tasks – allowing developers and data scientists to focus more on analysis, interpretation and strategic issues. Companies that take data governance, data protection and data maintenance seriously right from the start of a project can develop their AI models more efficiently whilst complying with legal requirements. In short: data protection and data quality are not obstacles, but rather enable precisely the trustworthy and high-performing data on which successful AI initiatives are built.
Sources
- Marco Geuer: Establishing a Data-Inspired & Digital Culture, The Data Economist Blog (DE).
- Data Masking – Protection of Sensitive Data, JET Software.
- Brief Position: Personal Data in Software Development and Testing, BfDI – Technical Applications.